 实时调度
实时调度
调度系统就是这样,不能等着最优解自己出现,而是要利用技术,创造最优解!🎯
# 背景介绍 📖
想象一下,你点了一杯奶茶,希望它在30分钟内送到手中,而配送系统仍然在用“接到订单就慢慢计算路线”的方式派单——结果你等了1个小时,奶茶都凉了🥶。
这就是实时调度的魅力——它得快、准、狠,把每个环节的时间掐得死死的。不管是外卖、物流,还是设备管理,实时调度就像个“超级大脑”,得随时知道谁在干啥、啥时候干完、接下来干啥。 以前我们总觉得“来一条算一条”挺好,但后来发现,时代变了,数据量大了,这种老办法已经跟不上节奏了。
# 从问题到方案
# 为啥传统办法不行?
一开始,我们的想法很简单:来一条订单,算一条呗,存到MySQL里,需要啥就查啥,多省事!但现实给了我们一记响亮的耳光。
- 问题1:数据量大了,MySQL扛不住 💥
当订单量从几百跳到几万,甚至几十万时,MySQL的查询速度开始“龟速前进”。你想想,查个表还得加锁,算个结果还得扫全表,调度哪还有“实时”可言?
问题2:批处理像「延迟邮差」🐌
-- 每小时统计一次的订单看板 SELECT * FROM orders WHERE create_time > NOW() - INTERVAL 1 HOUR;1
2
3问题3:单条计算太“短视” 😫 假如一个骑手刚送完单,你单独算这条订单,可能觉得他闲着。但其实他下一秒就被另一单占了,这种“只看眼前”的算法根本没法全局优化。
# 总结
- 逐条计算,无法应对高并发:MySQL等关系型数据库适合存储和查询,但不擅长高吞吐的流式计算。
- 查询压力大,影响业务性能:直接查MySQL,在大规模并发下,查询会变得缓慢。
- 缺乏实时性,无法快速决策:调度涉及多个环节,每个环节的延迟都会累积,导致整体调度失效。
传统架构像「俄罗斯套娃」业务系统→Redis→MQ→Hive→MySQL,数据流转就像玩击鼓传花,等传到决策层手里,黄花菜都凉了。
那咋办呢?我们开始找更厉害的工具,这才盯上了Flink和Clickhouse。
# Flink + Click
- Flink:实时计算的「闪电侠」⚡
Flink是个实时流处理的专家,能把数据当成一条“流水线”,边来边算,还能记住历史的“上下文”。比如,它能实时分析设备的位置、订单的紧急程度,瞬间给出最优派单方案。比起传统“攒一堆再算”,Flink简直是“未卜先知”。
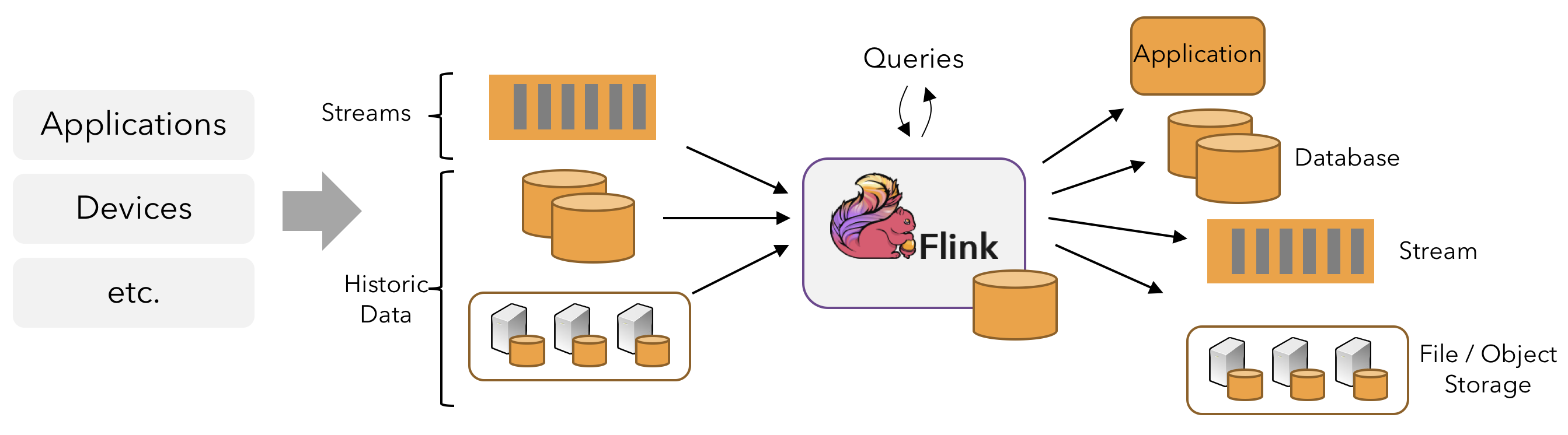
- Clickhouse:分析查询的「快银」💨
Clickhouse是个列式数据库,查询速度快得飞起,特别适合那种“给我10分钟内所有订单状态”的需求。MySQL查这个可能要喘口气,Clickhouse直接秒出结果。
# 对比
| 维度 | 传统架构(MySQL) | Flink + ClickHouse |
|---|---|---|
| 实时性 | 秒级~分钟级延迟 | 毫秒级~秒级延迟 |
| 吞吐量 | 单机万级TPS,扩展困难 | 分布式百万级TPS,线性扩展 |
| 复杂计算支持 | 依赖代码实现,难以处理乱序事件/状态管理 | 内置窗口函数、状态后端、CEP库 |
| 存储成本 | 行式存储,压缩率低 | 列式存储,压缩率高(节省50%+存储空间) |
| 扩展性 | 垂直扩展(硬件升级),分库分表成本高 | 水平扩展(增加节点),自动分片与负载均衡 |
| 容错能力 | 依赖数据库事务,故障恢复时间长 | Checkpoint + 副本机制,秒级故障恢复 |
# 八大环节的「实时调度交响曲」🎻
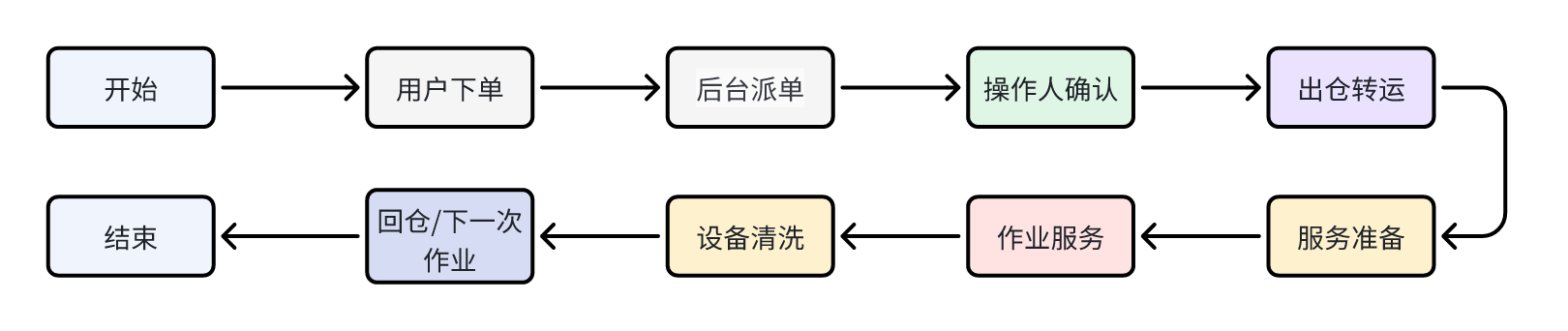 调度涉及多个步骤,每一步都要精准计算。
调度涉及多个步骤,每一步都要精准计算。
1️⃣ 用户下单
订单数据进入 Flink 流计算,分析订单属性(紧急程度、用户信用等)。
2️⃣ 后台派单
计算最优服务人员,结合历史数据(ClickHouse)+ 实时状态(Flink)。
3️⃣ 操作手确认
实时判断服务人员位置、任务情况,避免重复派单或超载。
4️⃣ 出仓转运
计算最佳路线、运力分配,结合交通流量等数据。
5️⃣ 服务准备
确保工具、设备、人员就绪,减少等待时间。
6️⃣ 地头作业
监控作业进度,防止异常(如设备故障、时间超限等)。
7️⃣ 设备清洗
计算下一个作业地点或回仓需求,优化资源利用率。
8️⃣ 回仓/下一处作业
动态调度,避免不必要的空驶,提升效率。
# 踩坑指南与「真香定律」😅
- 乱序数据打脸事件
方案:Flink水印机制+EventTime
WatermarkStrategy<Order> strategy = WatermarkStrategy
.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event) -> event.getCreateTime());
2
3
- Flink窗口设置太死板
方案:一开始窗口时间设得太长,算出来的结果总是“迟到”。后来我们动态调整窗口大小,根据数据量和延迟需求灵活切换,总算赶上了趟
- Clickhouse数据一致性
方案:调整分区策略,避免热点查询。
- 调度规则复杂,计算逻辑优化困难
方案:使用 Flink SQL 提高可读性,减少手写代码的维护成本。
# 风险
- Flink的Checkpoint调优:配置不当可能导致作业恢复时间过长(如大状态作业的RocksDB性能问题)。
- 内存占用:Flink状态后端(如RocksDB)和ClickHouse的索引可能消耗大量内存,需合理分配资源。
- 技术栈多样性:同时维护Flink和ClickHouse两套系统,对团队技术栈深度要求较高,需投入额外学习成本。
# 展望
- Flink:调整Checkpoint间隔与并行度,启用增量Checkpoint减少IO压力。
- 架构简化:探索Flink与ClickHouse的深度集成(如Flink直接访问ClickHouse的分布式引擎),减少组件依赖。
- 冷热数据分离:将历史调度数据从ClickHouse迁移至S3等低成本存储。
# 结语
调度系统就是这样,不能等着最优解自己出现,而是要利用技术,创造最优解!🎯