 flink第二弹
flink第二弹
# flink 架构
Flink采取master - worker的结构架构,主要包括两个组件
- Master: Flink作业的主进程,它主要起协调管理的作用
- TaskManager: 执行计算任务的进程,拥有CPU,内存等资源。Flink需要将计算任务发往多个taskmanger上并行执行任务。
# Flink作业提交的过程
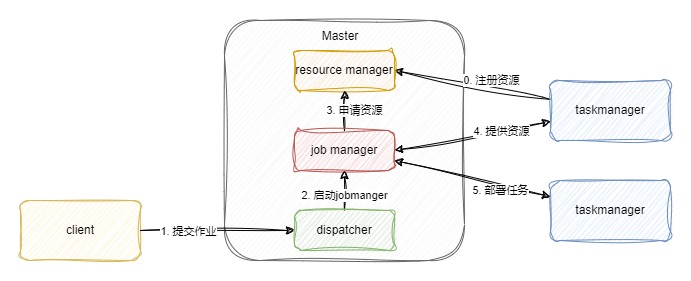
在一个作业提交前,master与taskmanager需要首先被启动。单机版flink直接使用bin/start-cluser命令进行启动,taskmanger启动后向Resource manger注册。这个流程在用户提交jar包前执行。
- 用户通过SDK编写好的程序,通过client进行提交。现在通常使用Java语言编写,构建逻辑视角数据流图。代码和相关配置文件进行打包编译构建,通过客户端提交到dispatcher,形成一个作业Job.
- Dispatcher收到这个作业之后,会启动Jobmanager,负责协调本次的工作。
- Jobmanger向Resource manager申请本次作业所需要的资源。
- 在整个flink刚启动时,taskmanger已经向resource manger注册,此时,闲置的taskmanager将会反馈给jobmanager。
- jobmanager将用户作业中的逻辑视图转换为物理执行图,将计算任务分发给多个taskmager。
一个Flink job开始执行!!!
# graph
public static void main(String[] args) throws Exception {
// 检查输入
final ParameterTool params = ParameterTool.fromArgs(args);
...
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data
DataStream<String> text =
env.socketTextStream(params.get("hostname"), params.getInt("port"), '\n', 0);
DataStream<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
.sum(1);
counts.print();
// execute program
env.execute("WordCount from SocketTextStream Example");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
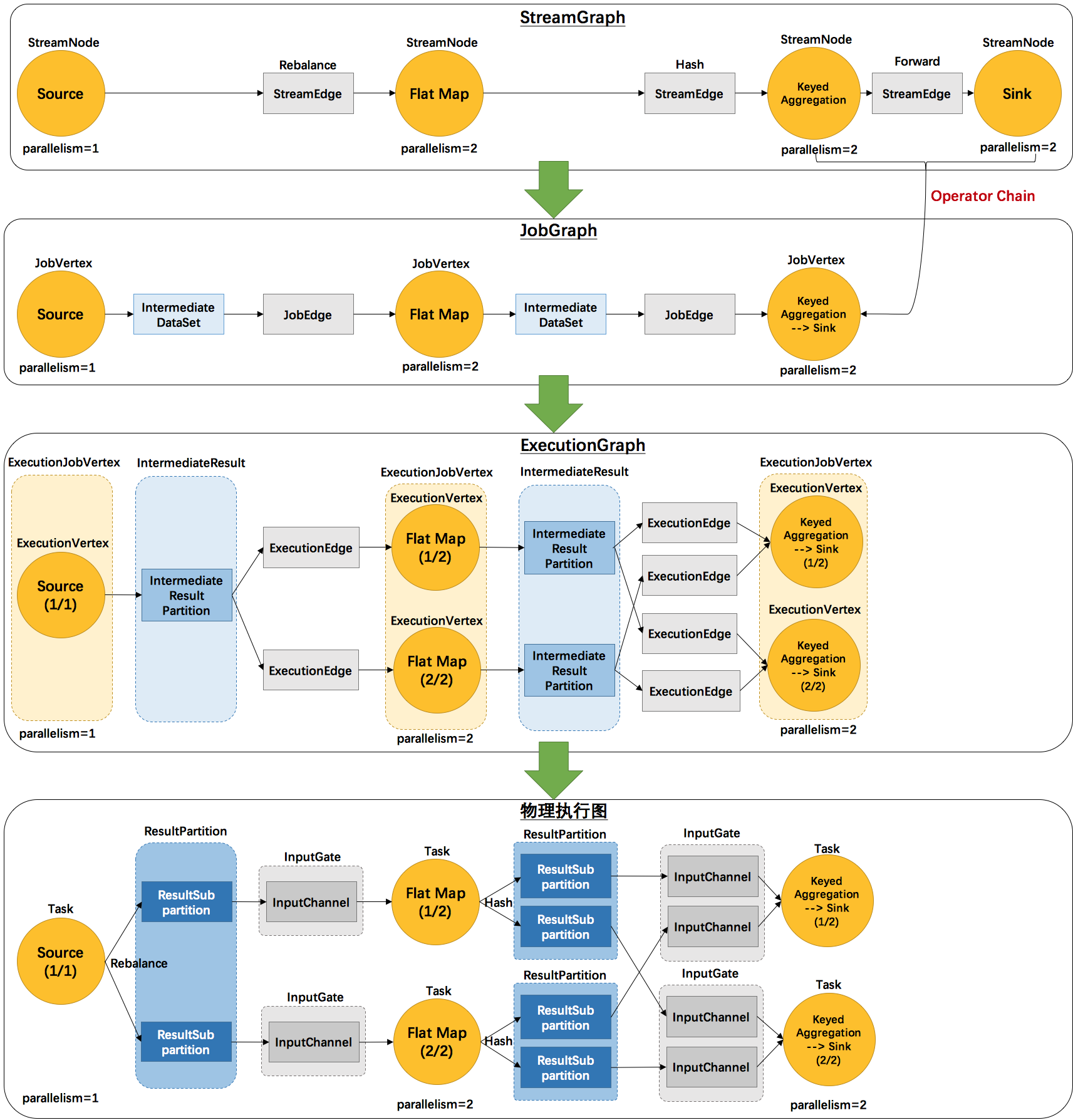
| 图 | 描述 | 细节 |
|---|---|---|
| StreamGraph | 根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。 | StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。 StreamEdge:表示连接两个StreamNode的边。 |
| JobGraph | StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。 | JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。 IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。 JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。 |
| ExecutionGraph | JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。 | ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。 IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。 IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。 Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。 |
| 物理执行图 | JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。 | Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。 ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。 ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。 InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。 InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。 |
# 任务执行 资源划分
算子子任务是Flink物理执行的基本单元,算子子任务之间是相互独立的,某个算子子任务有自己的线程,不同算子子任务可能分布在不同的机器节点上。算子子任务、分区、实例都是指对算子的并行切分
数据交换策略
| 策略 | 描述 |
|---|---|
| 前向传播(Forward) | 前一个算子子任务直接传递数据给后一个算子子任务,避免了跨分区交换和相关开销。 |
| 按Key分组(Key-Based) | 数据以(Key, Value)形式存在,按Key进行分组,相同Key的数据分到同一组,发送到同一分区。在WordCount程序中,keyBy将单词作为Key,将相同单词发送到同一分区,便于后续算子的聚合统计。 |
| 广播(broadcase) | 将某份数据广播到所有分区,涉及全局数据的拷贝,因此资源消耗较大。 |
| 随机策略(Random) | 将所有数据均匀地随机发送到多个分区,确保数据平均分布到不同分区。通常用于防止数据倾斜到某些分区,导致部分分区数据稀疏,另一些分区数据拥挤。 |
# 任务槽位与计算资源
# Task Slot
- TaskManager 是一个JVM进程,taskManager可以管理一至多个Task
- 每个Task是一个线程,占用一个slot
- 每个slot是taskManager资源的子集
# 槽位共享
Slot Sharing,进一步优化数据传输开销,充分利用计算资源。 Flink的一个槽位可能运行一个算子任务;也可以是被链接的多个子任务组成的Task,或者是共享槽位的多个Task。
# time
# Event Time
Event Time指的是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间。由于事件从发生到进入Flink时间算子之间有很多环节,一个较早发生的事件因为延迟可能较晚到达,因此使用Event Time意味着事件到达有可能是乱序的。
使用Event Time时,最理想的情况下,我们可以一直等待所有的事件到达后再进行时间窗口的处理。假设一个时间窗口内的所有数据都已经到达,基于Event Time的流处理会得到正确且一致的结果。无论我们是将同一个程序部署在不同的计算环境,还是在相同的环境下多次计算同一份数据,都能够得到同样的计算结果。我们根本不同担心乱序到达的问题。
但这只是理想情况,现实中无法实现,因为我们既不知道究竟要等多长时间才能确认所有事件都已经到达,更不可能无限地一直等待下去。在实际应用中,当涉及到对事件按照时间窗口进行统计时,Flink会将窗口内的事件缓存下来,直到接收到一个Watermark,Watermark假设不会有更晚数据的到达。Watermark意味着在一个时间窗口下,Flink会等待一个有限的时间,这在一定程度上降低了计算结果的绝对准确性,而且增加了系统的延迟。比起其他几种时间语义,使用Event Time的好处是某个事件的时间是确定的,这样能够保证计算结果在一定程度上的可预测性。
一个基于Event Time的Flink程序中必须定义:一、每条数据的Event Time时间戳作为Event Tme,二、如何生成Watermark。我们可以使用数据自带的时间作为Event Time,也可以在数据到达Flink后人为给Event Time赋值。
总之,使用Event Time的优势是结果的可预测性,缺点是缓存较大,增加了延迟,且调试和定位问题更复杂。
# Processing Time
对于某个算子来说,Processing Time指算子使用当前机器的系统时钟时间。在Processing Time的时间窗口场景下,无论事件什么时候发生,只要该事件在某个时间段到达了某个算子,就会被归结到该窗口下,不需要Watermark机制。对于一个程序,在同一个计算环境来说,每个算子都有一定的耗时,同一个事件的Processing Time,第n个算子和第n+1个算子不同。如果一个程序在不同的集群和环境下执行,限于软硬件因素,不同环境下前序算子处理速度不同,对于下游算子来说,事件的Processing Time也会不同,不同环境下时间窗口的计算结果会发生变化。因此,Processing Time在时间窗口下的计算会有不确定性。
Processing Time只依赖当前执行机器的系统时钟,不需要依赖Watermark,无需缓存。Processing Time是实现起来非常简单,也是延迟最小的一种时间语义。
# Ingestion Time
Ingestion Time是事件到达Flink Source的时间。从Source到下游各个算子中间可能有很多计算环节,任何一个算子的处理速度快慢可能影响到下游算子的Processing Time。而Ingestion Time定义的是数据流最早进入Flink的时间,因此不会被算子处理速度影响。
Ingestion Time通常是Event Time和Processing Time之间的一个折中方案。比起Event Time,Ingestion Time可以不需要设置复杂的Watermark,因此也不需要太多缓存,延迟较低。比起Processing Time,Ingestion Time的时间是Source赋值的,一个事件在整个处理过程从头至尾都使用这个时间,而且后续算子不受前序算子处理速度的影响,计算结果相对准确一些,但计算成本比Processing Time稍高。
# 设置时间语义
# watermark
# window
# 参考
- http://wuchong.me/categories/Flink/
- https://lulaoshi.info/flink/chapter-system-design/dataflow.html